前置知识提示:读这篇前,建议了解:token、概率分布、交叉熵(见第 1、2、3 篇)。
模型在最后一步到底做了什么#
你和 ChatGPT 对话,发了一句「今天天气」,它回了一个「真」。你大概知道中间是 Transformer 在算,但具体是怎么从一个向量「挑」出「真」这个字的?
如果你看过 PyTorch 里 causal LM 推理时的代码,每一步生成下一个 token 的核心几行经常长这样:
hidden = transformer(input_ids) # [B, T, d]:每个位置一个 hidden state
last_logits = lm_head(hidden[:, -1, :]) # 只取最后一个位置 → [B, V]
probs = softmax(last_logits / temperature) # 归一化成概率分布
next_token = sample(probs) # 按概率采一个 token 出来为什么只取最后一个位置?因为推理时每一步只关心「接下来一个 token」,前面位置的 logits 在采样阶段用不上(训练时则要算每个位置的 loss,所有位置都用)。这四行是模型从「内部表示」到「输出 token」的最后一公里。每一行都不复杂,但藏着几个值得拆开看的东西:
- logits 是什么?为什么不直接算概率?
- softmax 为什么是 \(e^x / \sum e^x\),不是别的形式?
- 你有没有注意过,所有正经实现里 softmax 都先减一个 max——为什么?
- temperature(温度)这个参数听上去很玄乎,到底改了什么?
这四个问题串起来,就是这一篇要讲的全部。
从 hidden state 到 logits:模型的「原始打分」#
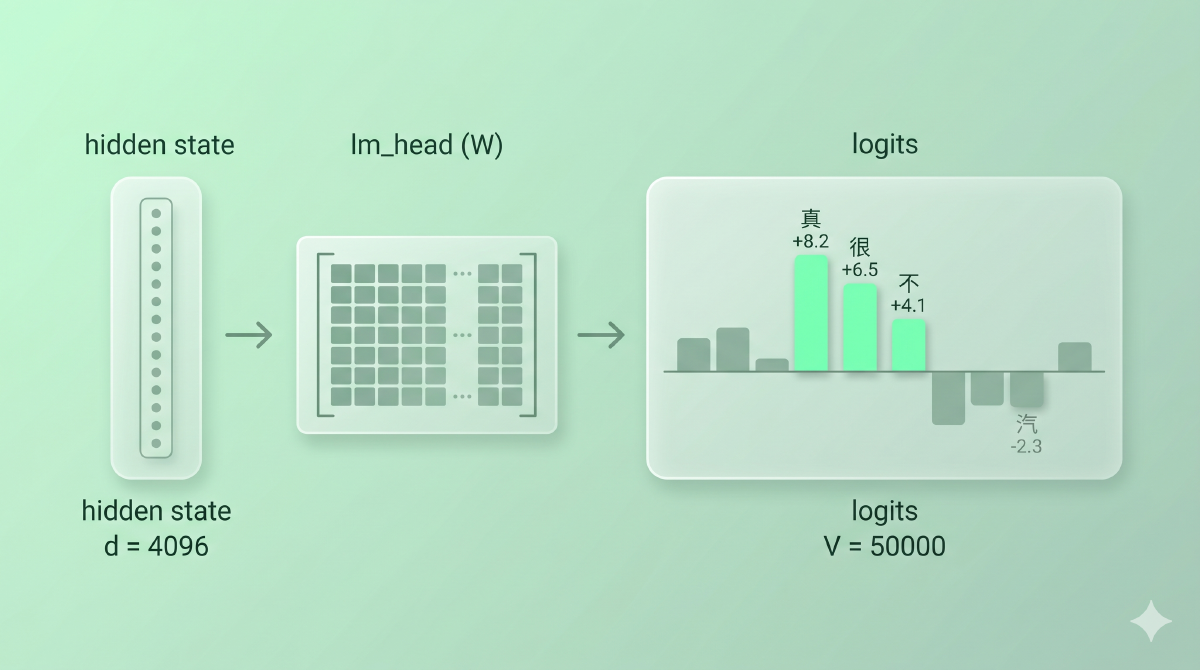
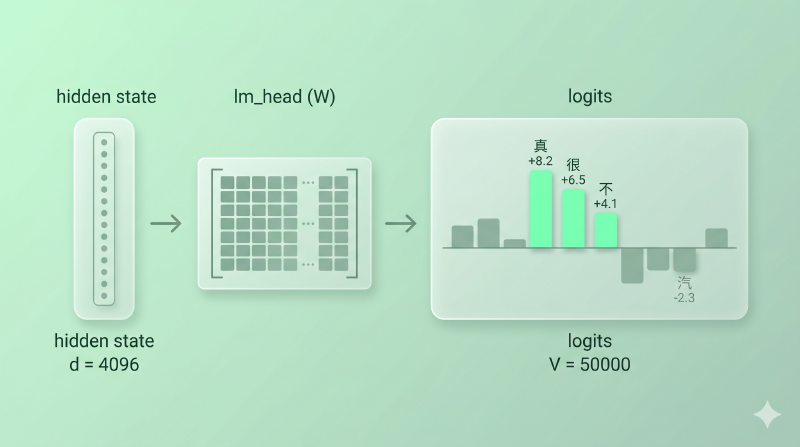
Transformer 的最后一层会给每个位置吐出一个向量——hidden state,比如 4096 维。但我们要预测的是下一个 token,词表可能有 50000 个候选。怎么从 4096 维变成 50000 维?
想象一个评委席。每个候选 token 是一个选手,模型对当前位置的理解(hidden state)就是选手的整体表现。最后要打分时,评委会把整体表现「投影」到每个选手身上,给每个人一个原始分——这就是 logits。
形式上,就是一个线性层:
$$ \text{logits} = h \cdot W^T + b $$其中 \(h \in \mathbb{R}^d\) 是 hidden state(比如 4096 维),\(W \in \mathbb{R}^{V \times d}\) 是输出投影矩阵(V 是词表大小),\(\text{logits} \in \mathbb{R}^V\) 是每个候选 token 的原始分。
这个 \(W\) 是模型的输出投影层,在代码里通常被命名为 lm_head。在做了 weight tying 的模型里,
lm_head的权重会与输入的 word embedding 共享——同一张 \(V \times d\) 的矩阵,输入时把 token id 查成向量,输出时把向量映射回每个 token 的分数,因此二者也常被一并称为 tied embedding(Press & Wolf, 2017)。共享权重能省下大约 \(V \times d\) 个参数,对 V = 50000、d = 4096 的模型,相当于节省约 2 亿参数。
关于 logits,有几个直觉值得记住:
- 可以是任何实数:正的、负的、几百几千都正常。logits 没有「合法范围」
- 越大越倾向:某个 token 的 logit 越大,模型越觉得它该出现
- 绝对值不重要,相对差才重要:logit = [10, 8, 5] 和 [100, 98, 95] 经过 softmax 是同一个分布——下一节会看到为什么
那为什么不让模型直接输出概率,省一道工序?两个原因:一是线性层输出实数比直接输出「和为 1 的非负向量」自然得多,省去了模型内部的归一化负担;二是 logits 比 probabilities 更适合配合 cross-entropy / log-softmax 做数值稳定的训练——这一点本文第三节会展开。
下一步要做的,就是把这组原始分翻译成概率。
图:4096 维 hidden state 通过 lm_head 线性层变成 V = 50000 维的 logits,每个候选 token 拿到一个原始分(可正可负)
Softmax:把任意实数变成概率分布#
我们手上现在有 V 个 logits,每个都是任意实数。要采样下一个 token,得先把它们变成一个合法的概率分布——即每个值在 [0, 1] 之间、加起来等于 1。
想象班级里评「最受欢迎」。每个同学有一个票数(可能是负的——比如有人投反对票)。你想算每个同学被选中的概率,怎么办?最自然的做法:先把所有票数取指数(让正票拉开差距、负票压到几乎为零),再除以总和(归一化)。
这就是 Softmax:
$$ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{V} e^{z_j}} $$为什么是这个形式?三个性质让它成为标准选择:
- 指数让所有值变正:\(e^x\) 永远 > 0,无论 \(x\) 是正是负
- 指数放大相对差异:任意两个候选 token 的概率之比满足 \(p_i / p_j = e^{z_i - z_j}\)——logit 差 1,二者的相对概率比就差约 \(e \approx 2.72\) 倍,差 5 就是约 148 倍。这符合「模型更偏好的 token 应当显著更可能」的直觉
- 平滑可微:在 logit 上的微小扰动会导致概率上的微小变化,梯度可以反传
需要补一句:softmax 并不是把实数变成概率分布的唯一方式,归一化的非负函数(如 normalized ReLU)、稀疏 softmax(sparsemax)等都是合法选择。它只是综合了「全空间可微」「指数让差距清晰」「与最大似然/交叉熵天然契合」这几条之后,最方便训练、生态最完善的那个。
来个具体例子。假设 logits = [2.0, 1.0, 0.1](三个候选 token):
import math
logits = [2.0, 1.0, 0.1]
exps = [math.exp(z) for z in logits] # [7.39, 2.72, 1.11]
total = sum(exps) # 11.22
probs = [e / total for e in exps] # [0.659, 0.242, 0.099]
# 第一个 token 大约 65.9% 概率,第二个 24.2%,第三个 9.9%Softmax 还有一个重要的性质:整体平移不变。把所有 logits 加上同一个常数 \(c\),分子和分母里都会多出一个 \(e^c\) 因子,可以约掉——结果完全不变。
用大白话说:只要 logits 之间的相对差不变,加减一个常数对最终概率没有任何影响。 这条性质看起来像数学小技巧,但下一节会看到,它就是工程实现里救命的那张牌。
减 max 与 log-sum-exp:为什么 softmax 必须「小心写」#
到这里,公式已经讲完了,理论上你可以直接照着写:
# 最朴素的写法
def naive_softmax(logits):
exps = [math.exp(z) for z in logits]
total = sum(exps)
return [e / total for e in exps]但这段代码在工程上会爆炸。原因是浮点数。
想象一根温度计,刻度从 -200°C 到 +200°C。你想测一锅煮沸的水(100°C),没问题;要测太阳表面温度(5500°C),温度计直接读「上溢」——给不出答案。浮点数也一样:能表示的范围有上限。
float32 能表示的最大值大约是 \(3.4 \times 10^{38}\),对应 \(e^x\) 的最大输入 \(x \approx 88.7\)。这个数听上去不小,但训练初期、异常 batch、温度或缩放设置不当,又或者输入本身数值病态时,logits 完全可能突破这个上限。一旦某个 \(e^{z_j}\) 上溢成 inf,再做归一化(inf / inf)就是 NaN——整个 batch 的训练就坏了。这种事通常不会立刻报错,往往是 loss 几小时后突然变 NaN,回头去查才发现。
救命的就是上一节那个性质:整体平移不变。把所有 logits 减去其中的最大值 \(M = \max_j z_j\),再做 softmax:
$$ \text{softmax}(z_i) = \frac{e^{z_i - M}}{\sum_j e^{z_j - M}} $$减完之后,最大的那个 logit 变成 0(\(e^0 = 1\)),其他的全是负数(\(e^{\text{负数}} \in (0, 1]\))——再也不会上溢。结果和原版完全相同,只是数值上安全。
def stable_softmax(logits):
M = max(logits)
exps = [math.exp(z - M) for z in logits]
total = sum(exps)
return [e / total for e in exps]这一行 max(logits) 不是为了「提高精度」,是为了「不让程序崩」。所有正经的深度学习库(PyTorch、JAX、TensorFlow)的 softmax 实现里都有这一步。
log-sum-exp:训练里的另一个隐形角色#
实际训练中,我们很少单独算 softmax——更常见的是算 log-softmax,因为交叉熵 loss 要的是对数概率:
$$ \log \text{softmax}(z_i) = z_i - \log \sum_j e^{z_j} $$那个 \(\log \sum_j e^{z_j}\) 叫做 log-sum-exp(LSE)。它也有一样的溢出问题,也用一样的减 max 套路解决:先把每个 \(z_j\) 减去 max \(M\),算完 LSE 再把 \(M\) 加回来——数学上等价,数值上安全。
PyTorch 里有现成的 torch.logsumexp,所有跟概率相关的稳定计算背后都是它:交叉熵 loss、Transformer 里 attention 的 softmax(\(QK^T / \sqrt{d}\) 之后那一步同样要减 max,否则长上下文里也会炸)、混合专家的路由打分……都共用这一套技巧。后面讲 attention 时不再单独提,默认它已经做了。
一句话:你看到的所有
softmax实现都不是教科书上那个公式的直译——它们都先减了 max。这不是优化,是底线。
Temperature:在 logits 上的一次缩放#
到这里 logits → softmax → probs 的链路已经完整。最后一个常被问到的概念是 温度(temperature)。
你可能在 ChatGPT 或 API 里见过这个参数:temperature=0.2 时回答严谨稳定,temperature=1.5 时跳脱发散。这个 T 到底改了什么?
想象一个音量旋钮。T 小(音量低)= 只能听见最响的那个声音,其他都被压下去;T 大(音量高)= 各种声音都能听见,差异变小。Temperature 在 logits 上的作用就是这个——用一个数压扁或拉开整个分布。
形式上简单到只有一步——在 softmax 之前先把 logits 除以 T:
$$ \text{softmax}_T(z_i) = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}} $$当 T 改变时:
- T = 1:标准 softmax,不动 logits
- T → 0(小):logits 被放大,最大的那个经过指数后远远超过其他——分布变得尖锐(peaky),几乎只采到 argmax
- T → ∞(大):logits 被压缩到接近 0——分布变得平坦(flat),趋近均匀分布
至于 temperature 在生成里具体怎么用、为什么有时候它「调了不起作用」、它和重复输出、模式崩塌、「胡说八道」之间到底是什么关系——那是本章后面专门一篇的事,这里不展开。本文只需要把这个机制看清楚:温度就是 softmax 之前在 logits 上的一次除法,其他所有效果都是从这一步推出去的。
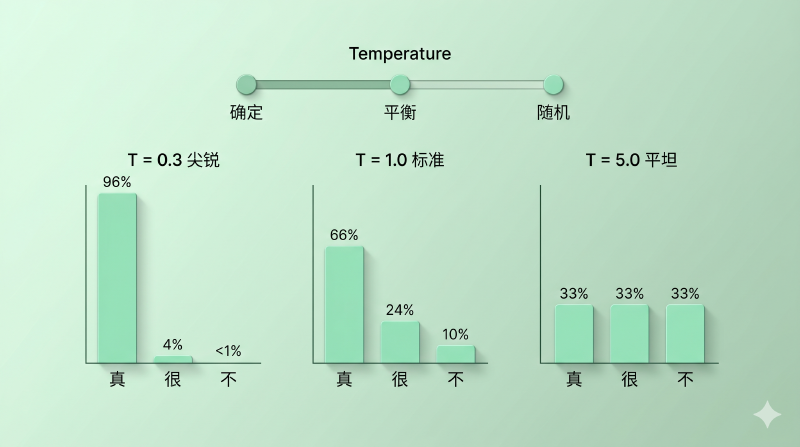
图:同一组 logits = [2.0, 1.0, 0.1],T 从 0.3 → 1.0 → 5.0,概率分布从尖锐(几乎只选第一个)变到平坦(接近均匀)
读完这篇,你拿到了什么#
我们把模型输出层的「最后一公里」完整拆了一遍:
- Logits:
lm_head把 hidden state 投影到词表维度的原始分,可正可负,没有「合法范围」 - Softmax:用指数把任意实数变成合法概率分布,关键性质是「平移不变」
- 数值稳定:所有 softmax 实现都先减 max,因为 float32 撑不住几百量级的指数;
logsumexp在 cross-entropy、attention 里都是同一招 - Temperature:本质就是 softmax 之前在 logits 上的一次除法,控制分布是尖锐还是平坦;具体怎么调、和「胡说八道」的关系,本章后面专门讲
从这一篇开始,你看 PyTorch 里那行 F.log_softmax(logits / T, dim=-1),应该不再觉得是「魔法咒语」——每个字符背后都有具体的工程考量。
但模型给了你一个完整的概率分布之后,怎么从里面挑一个 token 出来、什么时候停下来,本身就是另一门学问——是直接取最大(greedy),还是按分布随机抽?句子又是怎么知道该结束的?下一篇我们先把 decoding 的整体框架搭起来,再用接下来的几篇逐个拆采样策略和温度的实战细节。
参考资料 / 推荐阅读#
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning, Chapter 4.1 & 6.2.2.3(Softmax 的数值稳定与 log-sum-exp 推导)
- Hinton, G., Vinyals, O. & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv:1503.02531(温度参数在知识蒸馏中的经典用法)
- Press, O. & Wolf, L. (2017). Using the Output Embedding to Improve Language Models. arXiv:1608.05859(lm_head 与 input embedding 权重共享)
- PyTorch 文档:torch.nn.functional.log_softmax、torch.logsumexp


