

前置知识提示:读这篇前,建议了解:token、条件概率、链式法则(见第 1 篇)。
模型猜得准不准,总得有个打分标准#
上一篇我们说了,语言模型的工作是估计 \(P(x_t \mid x_{\lt t})\)——给定上下文,输出下一个 token 的概率分布。
但"估计"这个词藏着一个问题:模型给出的概率分布,和真实世界的概率分布,总有差距。训练的本质就是缩小这个差距。
那怎么衡量这个差距?
你可能会说:“看模型猜对了多少次。“这个直觉没错,但不够用——模型输出的不是一个答案,而是一整个概率分布。猜对的同时,我们还关心模型有多"确信”。同样猜对了"真"这个 token,一个模型给它 90% 的概率,另一个只给 30%,前者显然更好。
所以我们需要一个分数,既奖励"猜对”,又奖励"猜得自信"。
图:同样猜对"真",模型 A 给 90% vs 模型 B 给 30%——概率越高,打分越高
最大似然:让正确答案的概率尽可能大#
想象你是个天气预报员,每天预测明天下不下雨。年底考核的时候,领导怎么评价你?最直接的方式:把你每天给"实际结果"打的概率乘起来。如果某天下了雨,你当天给"下雨"的概率是 0.9,这一天你的得分就是 0.9;如果你只给了 0.3,得分就是 0.3。一年 365 天乘下来,这个总分就是你的似然(Likelihood)。
语言模型的训练用的是完全相同的思路。
假设训练数据里有一句话"今天天气真好。"(还是用上一篇的例子)。模型在每个位置对"正确答案"给出了一个概率:
- \(P(\text{今天} \mid \text{BOS}) = 0.02\)(词表很大,第一个词不好猜,0.02 已经不低了。BOS 是序列起始标记,和第 1 篇提到的一致;后面为简洁省略 BOS)
- \(P(\text{天气} \mid \text{今天}) = 0.15\)
- \(P(\text{真} \mid \text{今天天气}) = 0.25\)
- \(P(\text{好} \mid \text{今天天气真}) = 0.40\)
- \(P(\text{。} \mid \text{今天天气真好}) = 0.60\)
这句话的似然就是所有位置概率的乘积:
$$ L = 0.02 \times 0.15 \times 0.25 \times 0.40 \times 0.60 = 0.00018 $$最大似然估计(Maximum Likelihood Estimation, MLE) 的意思很直白:调整模型的参数,让这个乘积尽可能大。训练数据里有很多句话,就把每句话的似然全乘起来,让总乘积最大。
一句话概括:让模型在每个位置给正确答案打的概率都尽可能高。
从乘法到加法:对数登场#
最大似然的想法很干净,但直接优化有个工程上的致命问题:连乘导致数值下溢。
想象把 10000 个小于 1 的数乘在一起。0.3 × 0.2 × 0.5 × ……乘个几百步之后,结果就小到计算机的浮点数表示不了,直接变成 0。这不是数学问题,是计算机精度有限。
解决办法很经典:取对数。
对数有一个关键性质:\(\log(a \times b) = \log a + \log b\)。乘法变加法,连乘变求和,数值就稳了。
对似然取对数,得到对数似然(Log-Likelihood):
$$ \log L = \sum_{t=1}^{T} \log P(x_t \mid x_{\lt t}) $$每个 \(P(x_t \mid x_{\lt t})\) 都在 0 到 1 之间,取对数之后是负数。加起来还是负数,越接近 0 越好。
但优化领域的惯例是最小化目标函数(梯度下降是往下走的)。加个负号,把"最大化对数似然"翻转成"最小化负对数似然":
$$ \text{NLL} = -\sum_{t=1}^{T} \log P(x_t \mid x_{\lt t}) $$这就是 NLL(Negative Log-Likelihood),语言模型训练中最基础的 loss。
回到天气预报员的例子。你给下雨打了 0.9 的概率,\(-\log(0.9) \approx 0.105\),罚分很低;你只给了 0.3,\(-\log(0.3) \approx 1.204\),罚分翻了 10 倍不止。NLL 的惩罚机制天然对"自信地猜错"下重手——你越自信地猜错,罚得越狠。
用具体数字走一遍刚才的例子:
| 位置 | 正确 token | 模型给的概率 | \(-\log P\) |
|---|---|---|---|
| 1 | 今天 | 0.02 | 3.91 |
| 2 | 天气 | 0.15 | 1.90 |
| 3 | 真 | 0.25 | 1.39 |
| 4 | 好 | 0.40 | 0.92 |
| 5 | 。 | 0.60 | 0.51 |
NLL = 3.91 + 1.90 + 1.39 + 0.92 + 0.51 = 8.63
训练的目标就是让这个数尽可能小。
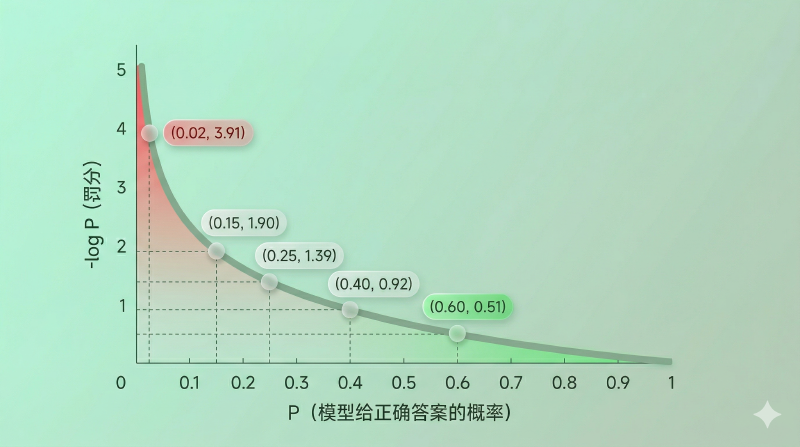
图:\(-\log p\) 曲线——概率越低罚分越重,且惩罚力度非线性增长
从一句话到整个数据集:交叉熵#
NLL 算的是一句话的总 loss。但不同句子长短不同,直接比总和不公平——就像考试,一张卷子 100 道题总分 90,和另一张 10 道题总分 50,不能直接比总分,得看平均。
所以实际训练时,我们把 NLL 除以 token 数量 T,取每个 token 的平均 loss:
$$ \mathcal{L} = -\frac{1}{T} \sum_{t=1}^{T} \log P(x_t \mid x_{\lt t}) $$这个式子,在形式上就是交叉熵(Cross-Entropy)。
交叉熵本身是信息论里的概念,衡量的是"用分布 Q 去编码服从分布 P 的数据,平均需要多少信息量"(用 \(\log_2\) 时单位是比特 bits,用自然对数 \(\ln\) 时单位是纳特 nats;深度学习里通常用自然对数,所以严格来说单位是 nats)。但在语言模型的场景下,你完全可以忘掉信息论的背景,直接理解为:每个 token 位置上,模型对正确答案的平均惩罚。
为什么恰好是这个形式?因为训练数据中每个位置的"真实分布"是一个 one-hot 向量——正确答案的概率是 1,其他所有 token 的概率是 0。把交叉熵的一般公式:
$$ H(P, Q) = -\sum_{x} P(x) \log Q(x) $$代入 one-hot 的 \(P\),只有正确答案那一项 \(P(x) = 1\) 活下来,其余全是 0,结果退化成了 \(-\log Q(x^*)\)——也就是 NLL。
在语言模型训练中,交叉熵 = 平均 NLL = 平均每个 token 的负对数概率。三种说法,同一件事。
用上面的例子:交叉熵 = 8.63 / 5 = 1.73。
补一个工程细节:真实训练时,通常是对一个 batch 中所有有效 token(排除 padding 等被 mask 的位置)的 loss 求平均,而非逐句算完再汇总。原理一样,只是粒度不同。
一段简单的 Python 代码可以帮你直观感受这个计算(注意:这里直接用概率是为了演示公式;实际训练中模型输出的是 logits——未归一化的分数,loss 函数内部会先做 log-softmax 再算 NLL):
import math
probs = [0.02, 0.15, 0.25, 0.40, 0.60] # 模型在每个位置给正确 token 的概率
nll = sum(-math.log(p) for p in probs) # NLL = 8.63
cross_entropy = nll / len(probs) # 交叉熵 = 1.73更深一层:模型到底在拟合什么#
到这里你可能会问:推了一圈数学,但训练目标为什么恰好是交叉熵?有没有比"好优化"更根本的理由?
有。换一个角度来看。
假设你要训练一个骰子模型。你扔了一万次真骰子,记录了每个面出现的频率。现在你要调你的模型骰子,让它的各面概率尽可能接近真骰子。怎么衡量"接近"?最自然的方式:真骰子出 1 的频率 16.7%,你的模型出 1 的概率也应该接近 16.7%——每一面都对齐。
语言模型面对的问题在结构上类似,但有一个关键区别:语言模型不是在拟合一个全局骰子——它在每个上下文 \(x_{\lt t}\) 下,都拟合一个独立的条件分布 \(P(\cdot \mid x_{\lt t})\)。“今天"后面跟什么和"昨天"后面跟什么,是两个不同的骰子。骰子类比帮你理解"让两个分布对齐"的思路,但语言模型要对齐的是数量庞大的条件分布族,不是一个单一的全局分布。
信息论告诉我们:当模型的概率分布 \(Q\) 和真实数据的经验分布 \(P\) 完全一致时,交叉熵 \(H(P, Q)\) 取到最小值——恰好等于数据本身的熵 \(H(P)\)。两者的差值就是 KL 散度(Kullback-Leibler Divergence),它永远大于等于零:
$$ H(P, Q) = H(P) + D_{\text{KL}}(P \| Q) $$\(H(P)\) 是数据本身决定的常数(训练数据一旦确定就不变),所以最小化交叉熵等价于最小化 KL 散度——让模型分布尽可能贴近数据分布。
这就是训练目标的深层含义:不是某种特设的优化技巧,而是在做一件最自然的事——让模型学到的分布逼近真实数据的分布。交叉熵恰好是衡量这个"差距"的正确工具。
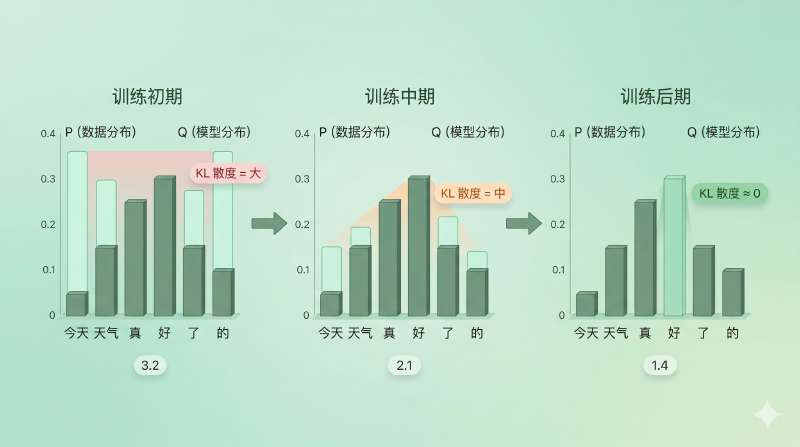
图:模型分布 Q 逐步逼近数据分布 P,KL 散度从大到小,交叉熵随之下降
读完这篇,你拿到了什么#
我们从一个朴素的问题出发——怎么定义模型"猜得准”——一步步走到了语言模型的训练目标:
- 最大似然:让模型在每个位置给正确答案的概率尽可能高
- 取对数:连乘变求和,解决数值下溢,得到 NLL
- 取平均:除以序列长度,得到交叉熵
- 深层含义:最小化交叉熵 = 最小化模型分布和数据分布的 KL 散度
从"预测下一个 token"到一个可优化的 loss 函数,中间的每一步都不是拍脑袋定的——环环相扣,有清晰的数学动机。
但 loss 再低,也只是训练时的内部指标——而且交叉熵的下降并不意味着下游任务表现线性提升,这中间还有很多值得拆的东西。眼下最直接的问题是:我们怎么向外界报告一个模型"有多好"?下一篇我们来看困惑度(Perplexity)——一个把交叉熵翻译成人类直觉的评估指标。
参考资料#
- Jurafsky, D. & Martin, J. H. Speech and Language Processing, Chapter 3: N-gram Language Models (§3.3 Evaluating Language Models)
- Goodfellow, I., Bengio, Y. & Courville, A. Deep Learning, Chapter 5: Machine Learning Basics (§5.5 Maximum Likelihood Estimation)
- Cover, T. M. & Thomas, J. A. Elements of Information Theory, Chapter 2: Entropy, Relative Entropy, and Mutual Information
- Murphy, K. P. Machine Learning: A Probabilistic Perspective, Chapter 8: Optimization

