

词表大小是序列长度与模型体积之间的一道权衡;而切分一旦定死,模型就看不见字母、对不齐数字。
前置知识提示:读这篇前,建议先了解 subword 子词、BPE / Byte-level BPE、Unigram 怎么把词表「学」出来(见第 9、10、11 篇)。
问一个最强的大模型:「strawberry 里有几个字母 r?」它可能一口咬定是两个。再让它把「lollipop」倒着拼出来,或者算一道位数多一点的乘法,它也常常翻车。
这就奇怪了。这些模型能写代码、能讲明白相对论,怎么连小学生都不会错的数字母、倒拼词、列竖式都做不利索?
一个流行的解释是「模型还不够聪明」。但真正的根子不在推理能力,而在更靠前的地方——它根本没在「看」字母,也没在按「位」看数字。要讲清这件事,得回到上一篇结尾留下的那个问题:分词器那张子词表到底该设多大;而它一旦定了下来,又把什么东西永久地挡在了模型的视野之外。
词表是个旋钮:调大调小,各付什么代价#
上一篇我们看到,BPE 和 Unigram 最后都能交付一张定长的子词表。可「定长」是多长?三万、五万还是十万?这个数字——词表大小(vocab size)——不是拍脑袋定的,它更像一个旋钮,拧动它,有两样东西会朝相反方向变。
把词表想成快递公司的「标准箱型表」。箱型越多越大,同样一批货打包的趟数就越少(序列更短);可你得在仓库里备齐每一种箱子,箱型越多,仓库越大越贵,而那些一年用不上几回的冷门箱型,工人甚至记不清怎么用(这些就是没学好的长尾 token)。箱型太少呢?仓库是省了,但什么都得拆成小箱、来回多跑几趟(序列被拉长)。
词表调大,单位文本被切成的 token 更少,序列就更短。序列短了,省的是两头:一头是上下文窗口——同样的 128k tokens 窗口能装下更多真实内容(呼应第 8 篇说的「token 是上下文窗口和计费共用的那把尺子」);另一头是计算量,注意力的开销随序列长度上涨,序列短了就省算力。听起来全是好处,可代价藏在模型的两端。
模型最前面有一张 embedding 矩阵,负责把每个 token id 查成一个向量;最后面有一个 softmax 输出层,负责给词表里每个 token 算一个概率。这两部分的规模都正比于词表大小 \(|V|\) 乘隐藏维度 \(d\) ,但到底是算一张表还是两张,取决于它们是否共享权重(weight tying,权重绑定):
$$ N_{\text{embed+head}} = \begin{cases} 2\,|V|\,d & \text{(untied)} \\ |V|\,d & \text{(tied)} \end{cases} $$有的模型让输入 embedding 和输出 softmax 各用一张表(untied,如 Llama 默认),这部分参数就是 \(2|V|d\) ;有的让两者绑定、共享同一套权重(tied,如 GPT-2 默认),参数减半到 \(|V|d\) 。但别被「减半」骗了:哪怕权重共享,softmax 每一步仍要给词表里每个 token 都算一个分数,这部分的计算量和显存照样随 \(|V|\) 线性增长。拿一个 \(d=4096\) 、词表 \(|V|=128000\) 的模型来算,单是绑定情形下的这一张表就约 5 亿参数——还没算中间任何一层 Transformer。一句大白话:词表翻倍,模型这两头的开销跟着涨。
更隐蔽的代价在长尾。第 8、9 篇提过,自然语言的词频服从 Zipf 分布:少数词极高频,大量词极低频。词表越大,被收进来的低频 token 就越多,可它们在训练语料里出现的次数太少,模型几乎没机会学好它们的向量——这个坑我们留到最后一节细说。
所以「词表该多大」是一道没有免费午餐的权衡题:大了省序列,却费参数、还养着一堆没学好的长尾;小了省参数,却把序列拉长、吃满窗口。主流模型就落在这条曲线的不同位置上——GPT-2 / GPT-3 用约 5 万的 BPE 词表,Llama 2 用 3.2 万,到了 GPT-4(cl100k)涨到约 10 万,更新的多语言模型常用 20 万往上。有意思的是,2024 年一篇研究(Tao 等)专门量化了这条权衡,结论是大多数模型的词表其实「开小了」:按它的估计,Llama 2-70B 这种体量本该配 20 万以上的词表,而不是 3.2 万。
图:拧动「词表大小」这个旋钮,序列长度和模型体积朝相反方向变——没有免费午餐
一刀切下去,字母就消失了#
回到开头那个 strawberry。为什么模型数不清里面有几个 r?因为它压根没看到那一串字母。
你以为模型读到的是 s-t-r-a-w-b-e-r-r-y 这十个字母,其实它读到的是两三个色块——大致像「str」「aw」「berry」这样的子词。让它数 r,相当于隔着毛玻璃去数一团马赛克里有几道红线:它看到的是块的整体,不是块里的笔画。
一个常用词在现代 tokenizer 里通常只占一到几个 token——「strawberry」往往被切成几个子词块(具体切成什么样因 tokenizer 而异),而不是摊开成十个字母。从输入到输出,模型见到的最小单位就是这些块。它当然「知道」strawberry 是什么意思(块的向量里编码了语义),但「这个词由哪些字母、按什么顺序组成」这种信息,在切分那一步就被打包进了块里、不再显式存在。数字母、倒着拼、按字母排序这类字符级任务,要的恰恰是被打包掉的那部分信息,于是频繁出错。
这里有个微妙之处值得说清:字母信息并不是彻底蒸发了。有研究(Kaushal & Mahowald, 2022)训练探针去预测「一个 token 里有没有某个字母」,发现 token 的向量里其实隐式编码了相当一部分字符构成,而且模型越大编得越准。只是这种信息是隐式、不稳定的——不像直接看到字符序列那样可靠,模型用起来时灵时不灵。所以更准确的说法是:分词把字符级任务的「显式输入」抽走了,逼模型去隐式地猜,于是表现飘忽。
这还要接上第 10 篇的一个点:BPE / BBPE 的切分是确定性的,同一个词每次都切成同样的块。这本是优点(结果可复现),可对字符级能力却是雪上加霜——模型从训练到推理,几乎总是看到 strawberry 被切成同一组块,很少有机会从「同一个词的不同切法」里反推它的字母构成(而这恰恰是上面那篇研究指出的、token 习得字符信息的途径之一)。切分越稳定,这种「看不见字母」就越是被焊死。
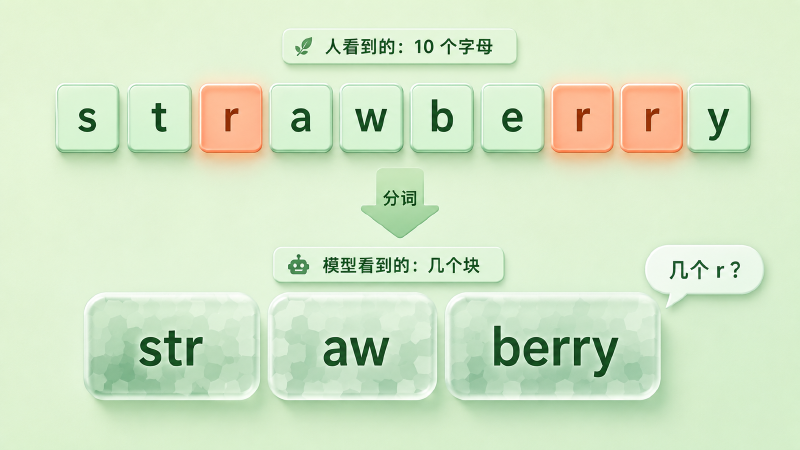
图:人看到 strawberry 的十个字母(三个 r 高亮),模型只看到几个不透明的子词块(此处「str·aw·berry」仅为示意,实际边界因 tokenizer 而异)——数 r 时它根本没在看字母
小结一句:模型不是不识字,是分词器替它把字打成了包。分词是字符级失败最重要的结构性瓶颈,但不是唯一原因——注意力机制、训练数据、任务形式都掺一脚;说到底,这跟「智商」关系不大。
数字算不对,是因为没对齐「位」#
再看算术。让模型算 1234 × 5678,或者比 9.11 和 9.9 谁大,它的出错率高得不正常。
列竖式的第一步是什么?对齐数位——个位对个位,十位对十位。可如果有人把「1234」剪成「12」「34」,又把「5678」剪成「5」「678」,长短不一、刀口还错位,这竖式你根本没法对着算。模型面对数字时,手里常常就是这样一沓乱剪的纸片。
问题出在数字怎么被切。早期 tokenizer(比如 GPT-2 / GPT-3 的 BPE)把数字当普通字符串、按频率合并:常见的「100」「2024」可能是一个 token,而「1235」也许被切成「12」+「35」,「1236」又切成「123」+「6」。同一个数位,在不同数字里落在不同的 token 边界上,于是「个位」「十位」这种按位对齐的结构被彻底打乱——可算术恰恰高度依赖位对齐。这就是 token 边界错位(token boundary mismatch)在数字上的表现。
这也是为什么很多模型专门在数字切法上动手脚。最直接的一招是把每个数字单独切成一个 token(Llama 系列就这么做),每一位都对应一个独立 token,位对齐自然就稳。另一招是按固定位数分组——GPT-3.5 / GPT-4 的 cl100k 给 1 到 3 位数字都留了 token。但「分了组」还不够,分组的方向才是关键:有研究(Singh & Strouse, 2024)发现,从低位起、按右对齐(R2L)分组,对加法明显更友好;而 cl100k 默认是从高位起、按左对齐(L2R)分组,一旦答案进位、长度变了,分组边界又会跟着错位、成绩掉得厉害。所以真正解决问题的不是「规整」两个字,而是「让切分跟着数位走」。
| 数字切法 | 代表 | 对算术 |
|---|---|---|
| 纯 BPE,按频率合并 | GPT-2 / GPT-3(p50k 等) | 边界最乱,最吃亏 |
| 1–3 位分组、左对齐(L2R) | GPT-3.5 / GPT-4(cl100k) | 分了组,但进位、变长时仍错位 |
| 三位分组、右对齐(R2L) | 研究中的改进方案 | 加法表现明显更好 |
| 每个数字单独成 token | Llama 系列 | 位对齐最稳、最直接 |
表:数字怎么切,直接决定了「位」对不对得齐——分组不如对齐重要
(至于 9.11 和 9.9 谁大这类问题,除了切分,还掺了训练语料里「9.11 > 9.9」这种版本号、章节号的干扰,是多因一果,但切分不规整始终是绕不开的一环。)
小结一句:不是模型不会算,是它拿到的数字本身就「对不齐位」。让切分跟着数位走(单数字,或低位右对齐分组),比逼模型「更努力地算」有效得多。
词表里的幽灵:glitch tokens#
最后一种毛病最诡异。有人发现,让某些 GPT 模型复述一个特定的词——比如 SolidGoldMagikarp——它会突然「失灵」:要么死活复述不出来,要么答非所问,甚至冒出些莫名其妙的话。
想象一所学校开学时按名册发了课桌,其中几个名字是从一份旧爬虫名单里抄来的,本人却从没来上过学。某天老师点到这个名字,全班一片茫然——座位是真的,人是空的。glitch token 就是词表里这样「占了座却没上过课」的条目。
这要从一个分裂说起:tokenizer 的训练语料,和模型本身的训练语料,往往不是同一批数据。分词器在它的语料里看到某个字符串频繁出现——比如某个论坛的高频用户名「SolidGoldMagikarp」(真实来源是 Reddit 一个计数版块的用户名)——就把它收成了一个独立 token。可到了训练模型时,这个字符串在主语料里几乎不出现,于是这个 token 的 embedding 几乎没被更新过,基本还停在初始的随机值。
当输入恰好命中这种 token,模型就被推到了一个它在训练中从没到过的向量位置,输出自然失控:复述失败、答非所问、甚至产生异常内容。这类 token 被称为 glitch tokens(故障 token),或欠训练 token(under-trained token)。它不是某个 bug,而是「分词器和模型各学各的、词表里混进了没被训练充分的条目」这道结构性裂缝的症状。2024 年一篇叫 Fishing for Magikarp 的论文专门研究了它,还给出了把这些幽灵 token 从词表里自动揪出来的方法。
小结一句:词表不是一张中立的清单,里面每个条目都得在训练中被「喂」够,否则就是一颗埋着的雷。
写在最后#
读到这里,「token 危机」这个词应该不再玄乎了。它其实是同一层裂缝长出的几副面孔:分词器为了在序列长度和模型体积之间取得平衡,必须定下一张词表、一套切分;而这套切分一旦定死,就顺手把字母、把数位一起封进了模型看不清的角落(这是 token 边界错位),同时还可能把一些没被训练充分的条目留在词表里(这是欠训练的 glitch token)。数不清 r、算不对乘法、撞上幽灵 token——表面是三件事,底下连着的是同一层的结构性代价。你的认知应该从「这些是模型不够聪明」,变成「这些是分词这一层欠下的账」。
那这账能不能还上?能,而且方向已经清楚——让模型重新「看见」字符(character-aware tokenizer、字节 / 字符兜底)、训练时随机采样不同切法(上一篇讲的 subword regularization 就是一例)、或者干脆把算术这类活儿外包给代码执行和外部工具。这些是另一条线上的话题,这里先按下不表。
也正因如此,分词这一章我们就走到了头:从第 8 篇的不可能三角,到 BPE、Unigram,再到今天的词表大小与 token 危机,我们一直在回答「一段字符流怎么变成一串 token id」。可 token id 说到底只是一串整数,模型并不能直接拿整数做运算。下一篇 #13,我们就跨进这一章的后半场——这些离散的 id 是怎么变成一个个连续向量的,也就是 embedding 查表,那「从离散到连续的惊险一跃」。
参考资料#
- Tao, C., et al. (2024). Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies. NeurIPS 2024. https://arxiv.org/abs/2407.13623 ——量化词表大小的权衡,指出多数模型的词表其实偏小。
- Singh, A. K., & Strouse, DJ. (2024). Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs. arXiv:2402.14903. https://arxiv.org/abs/2402.14903 ——系统比较单数字 / 多位数字、左右对齐分组对算术的影响。
- Land, S., & Bartolo, M. (2024). Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models. EMNLP 2024. https://arxiv.org/abs/2405.05417 ——系统研究 glitch / 欠训练 token 及其自动检测,标题正出自 SolidGoldMagikarp。
- Kaushal, A., & Mahowald, K. (2022). What do tokens know about their characters and how do they know it? NAACL 2022. https://arxiv.org/abs/2206.02608 ——探针实验证明 token 向量隐式编码了字符信息,模型越大编得越准。
- 延伸阅读:Rumbelow, J., & Watkins, M. (2023). SolidGoldMagikarp (plus, prompt generation). LessWrong——glitch token 现象最早的公开记录。https://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation


