前置知识提示:本篇是 LLM 系列的第一篇,零基础起步,不需要预备知识。如果你知道什么是概率,就能跟完全程。
这一章要解决一个最根本的问题:语言模型在数学上到底是个什么东西?
我们会从"一句话的概率怎么算"讲起,经过训练目标(交叉熵)、评估指标(困惑度)、模型输出的工程细节(logits 与 softmax),一路走到生成时的解码策略与采样参数。读完这一章,你会对"语言模型"这四个字有一个扎实的形式化理解——从概率定义、训练优化、到推理生成,形成一条完整的链路。
从输入法说起#
你在手机上打字,输入"今天天气",输入法弹出的第一个建议是"真好"。
换一个场景:你输入"今天股市",建议变成了"大跌"或"收涨"。
输入法在做什么?它在猜下一个词。而"猜"这件事如果要做得靠谱,就得回答一个问题:给定前面已经出现的词,下一个词是什么的可能性最大?
这就是语言模型最核心的工作——只不过它不是猜一个词,而是对一整句话的每个位置都给出概率。
那问题来了:一整句话的概率,怎么算?

图:给定"今天天气",模型预测下一个词的概率排序
一句话的概率:从整体到拆解#
想象你手里有一副扑克牌,要连续抽出黑桃 A、红心 K、方块 3 这三张,顺序也不能错。整件事发生的概率,等于第一张抽对的概率,乘以第一张对了之后第二张抽对的概率,再乘以前两张都对了之后第三张抽对的概率。一步一步乘下来,就是整件事的概率。
语言模型做的事情和这副扑克牌完全一样。
假设有一句话包含 T 个 token(token 是模型处理文本的最小单位,你暂时可以理解为"词"或"字"——但这里的切分仅为说明链式法则,真实的 tokenizer 未必这样切,我们在第二章会详细拆)。我们想知道这句话出现的概率 \(P(x_1, x_2, \ldots, x_T)\) 。
根据概率论中的链式法则(Chain Rule),这个联合概率可以精确地拆成一连串条件概率的乘积:
$$ P(x_1, x_2, \ldots, x_T) = \prod_{t=1}^{T} P(x_t \mid x_1, x_2, \ldots, x_{t-1}) $$别被符号吓到,这个公式说的事情很朴素:
一句话的概率 = 第一个词出现的概率 × 在第一个词已知时第二个词出现的概率 × 在前两个词已知时第三个词出现的概率 × …… 一直乘到最后一个词。
每一步的"已知信息"就是前面已经出现的所有 token,在这个领域里我们管它叫上下文(Context)。这也是你经常听到的"上下文窗口"的来源——它就是模型做每一步预测时能"看到"的历史信息。
我们通常把 \(x_1, x_2, \ldots, x_{t-1}\) 简写成 \(x_{\lt t}\),于是公式变得更简洁:
$$ P(x_{1:T}) = \prod_{t=1}^{T} P(x_t \mid x_{\lt t}) $$这就是语言建模的数学定义。一行公式,没有任何近似。
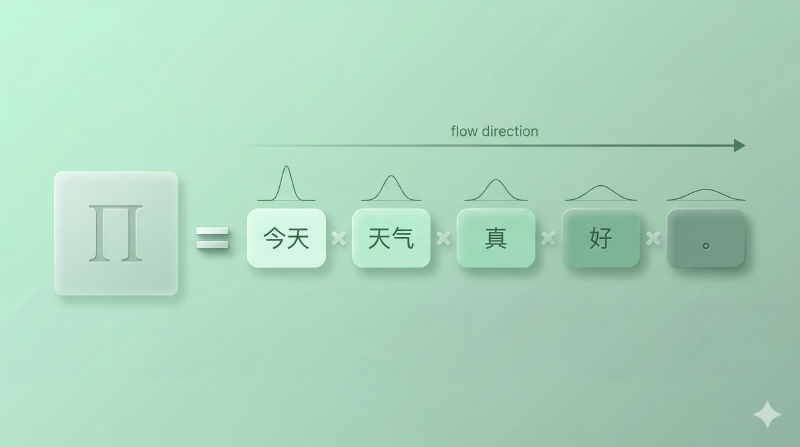
图:链式法则——“今天天气真好。“的概率被拆成五步条件概率的连乘
走一遍具体的例子#
拿一句话试试:“今天天气真好”。
假设模型把它切成 5 个 token:今天、天气、真、好、。(提醒:这里的切分只是为了演示链式法则的运作方式,实际 tokenizer 的切分规则会在第二章详细讲)。那这句话的概率就是:
每一步,模型都在做同一件事:看前面的所有 token,预测下一个 token 的概率分布。
这里有一个容易被忽略的点:第一个 token \(P(\text{今天})\) 没有上下文。实际操作中,模型通常会在序列开头加一个特殊的起始标记(比如 <BOS>),让第一个 token 也有东西可以条件依赖。
回到我们开头的输入法例子。当你输入"今天天气"的时候,输入法背后的语言模型在算的就是 \(P(\text{真好} \mid \text{今天天气})\) 和 \(P(\text{不错} \mid \text{今天天气})\) 哪个更大——然后把概率高的那个排在建议列表前面。
为什么是乘法而不是加法#
你可能会问:为什么是连乘?每个位置的概率加起来不行吗?
还是用扑克牌的例子。你连续抽两张牌,第一张抽中红心的概率是 1/4,第二张抽中 A 的概率是 1/13。“先红心后 A"这件事的概率是 1/4 × 1/13 = 1/52,不是 1/4 + 1/13。两件事都要发生,概率相乘;两件事发生一件就行,概率才相加。
语言模型里的每个 token 都得"猜对”,整句话才算成立——这是"都要发生"的场景,所以是乘法。
这也解释了一个直觉上很对的现象:句子越长,概率越低。因为每多一步连乘,概率只会更小或不变,不会变大。这不是 bug,而是客观现实——长句子本来就比短句子更"稀有”,可能的排列组合更多,任何一个具体的长句出现的概率自然更低。
正因为如此,实际比较不同模型或不同句子时,我们不会直接比原始概率(否则短句永远赢),而是用平均负对数概率 做长度归一化——这就是后续篇目要讲的困惑度(Perplexity)的核心思路。
语言模型 = 一个条件概率估计器#
到这里我们可以给语言模型下一个干净的定义。需要先澄清一点:本篇(以及本系列的主线)讨论的是自回归语言模型(Autoregressive Language Model)——它从左到右逐步预测下一个 token。你可能听说过 BERT 这类模型,它用的是另一种建模方式(遮住中间的词来预测),并不按这条左到右的链式分解来工作。我们这里聚焦的是 GPT、Claude、Llama 这条主流路线。
自回归语言模型就是一个函数,输入上下文 \(x_{\lt t}\),输出词表上每个 token 在下一个位置出现的条件概率 \(P(x_t \mid x_{\lt t})\)。
这个定义适用于所有自回归语言模型——从最早的 n-gram 模型到今天的 GPT、Claude、Llama。它们的差别不在于"建模什么”,而在于"怎么估计这个条件概率"。n-gram 靠数频率(数前面几个词出现后下一个词出现了几次),神经网络靠训练一个参数化的模型来逼近。
但这里有个坑。模型在训练的时候,需要一大堆文本来学习这些条件概率。训练的做法是:把一句真实的话拿来,在每个位置上让模型预测下一个 token,然后拿模型的预测和真实答案比对——预测得越准,loss 越低。
注意,训练时每个位置的"上下文"用的是真实文本,不是模型自己之前预测的结果。这种做法叫 teacher forcing——相当于老师在旁边按住答案,让学生每一步都看着正确的前文来预测下一步。
为什么不让模型用自己之前的预测当上下文?因为如果训练时直接喂模型自己的预测,误差会更容易累积,优化也会更不稳定——尤其在训练初期,模型预测得很差,错误的输入会导致后续预测越偏越远。因此实践中通常采用 teacher forcing,让训练过程更稳定、收敛更快。我们在后续篇目会展开聊它的利弊。

图:给定上下文"今天 天气",模型为下一个位置输出概率分布——“真"的概率最高
读完这篇,你拿到了什么#
我们从输入法的"猜词"开始,走到了语言建模的数学定义:一句话的概率等于逐 token 条件概率的连乘。这不是某个特定模型的设定,而是概率论的恒等式——链式法则。
所有自回归语言模型的工作,都可以归结为一件事:学会估计 \(P(x_t \mid x_{\lt t})\) 这个条件概率。模型的架构、训练方法、数据规模,本质上都是在让这个估计更准。
但这里还有一个问题没解决:模型怎么"学会"估计这个条件概率?我们说"预测得越准,loss 越低”,那这个 loss 到底是什么?下一篇我们来拆训练目标——从最大似然到交叉熵,看看"预测下一个 token"这件事是怎么变成一个可优化的数学问题的。
参考资料#
- Jurafsky, D. & Martin, J. H. Speech and Language Processing, Chapter 3: N-gram Language Models
- Bengio, Y. et al. (2003). A Neural Probabilistic Language Model. JMLR
- 3Blue1Brown. “But what is a GPT? Visual intro to Transformers” (YouTube)
- Williams, R. J. & Zipser, D. (1989). A Learning Algorithm for Continually Running Fully Recurrent Neural Networks. Neural Computation